使其崩溃
在前一节中我们已经看到了用传统的对象加异常的方式来建立容错系统是多么困难。 让我来看看actor是如何简化的。 当actor在处理消息时发生异常会如何处理? 我们已经讨论过为什么不想让容错代码跟业务处理混在一起,所有在业务逻辑的actor内部捕获异常是理所当然的。
akka没有用一个流程来处理正常代码和故障恢复代码,而是用两个不同的流程; 一个用于正常逻辑,一个用于故障恢复逻辑。 正常流程用于处理正常的消息,故障恢复流程包含一个actor用来检测正常流程的actor。 这个检测actor被称作supervisor。下图显示了supervisor检测actor的流程。

我就让actor崩溃,而不是在actor内部捕获异常。 actor的代码只包含正常逻辑,没有异常处理和故障恢复,所以它不是故障恢复的一部分,这使得问题更清晰。 崩溃actor的邮箱会被挂起,直到故障恢复中的supervisor决定如何来处理这个异常为止。 那如何让一个actor成为supervisor? akka让父actor作为supervisor,只要这个actor创建了其他actor,它就自动变为supervisor。 supervisor不捕获异常,而是监督失败的原因并给出一些策略。 supervisor也不去尝试恢复actor或者actor的状态。 它提供如何恢复的判断,然后触发相应的策略。 supervisor为如何操作actor提供了4个选项:
- 重启:actor会通过它的props重建。重启之后它会继续处理它的消息。 由于应用程序的其他部分是用actor的引用进行通信,所以新的actor实例会自动获取下一条消息。
- 恢复:同样的actor实例继续处理消息,忽略崩溃。
- 停止:actor必须停止,它不能再进行消息处理。
- 上报:supervisor不知道该如何处理,上报给自己的supervisor。
下图是用actor实现的日志处理程序实例。 当一个特定的崩溃发生时,supervisor需要采取一个特定的动作。
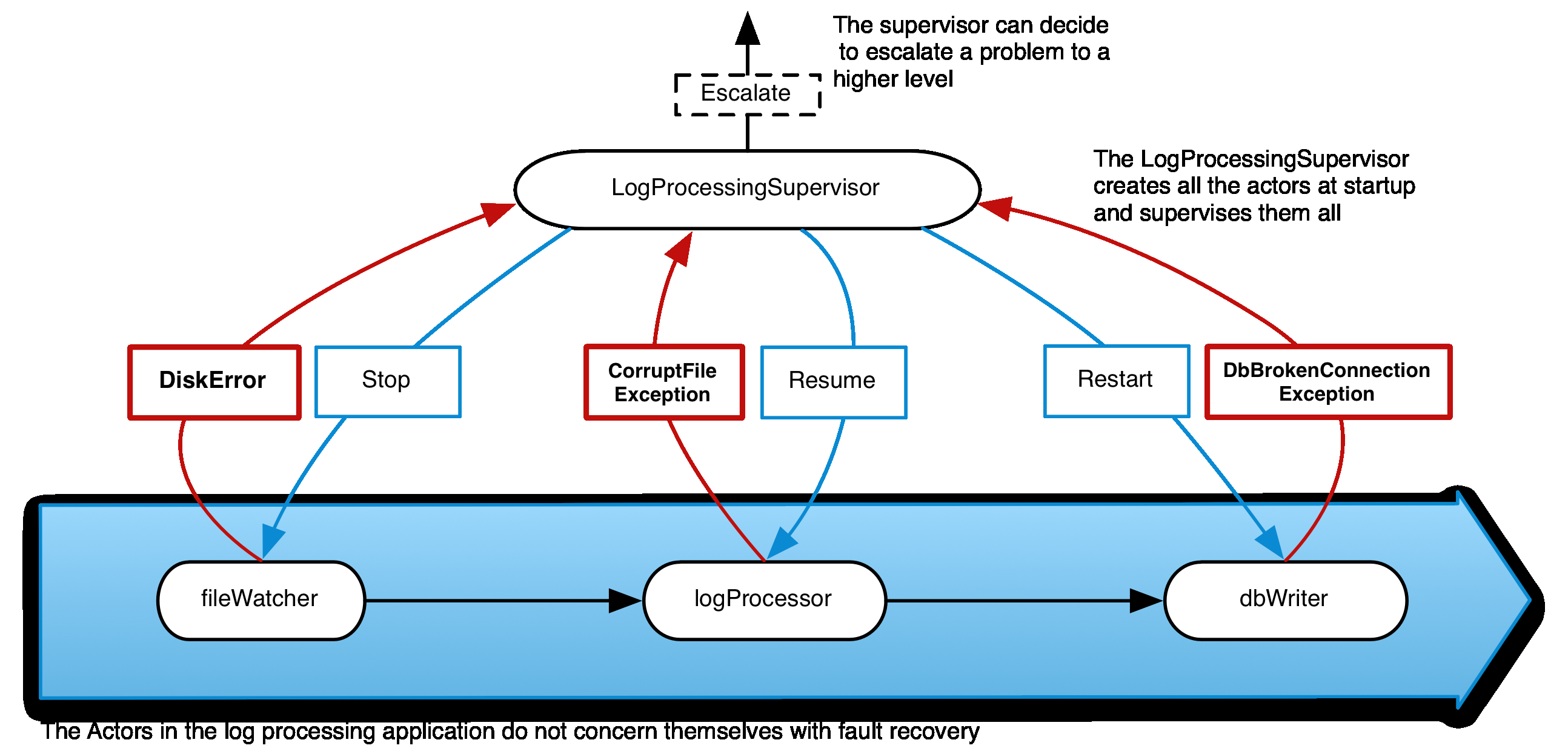
上图显示了日志处理程序的容错方案,只少是数据库连接异常的容错方案。 当dbWriter actor发生错误时,抛出DbBrokenConnectionException异常,LogProcessingSupervisor会重新创建一个dbWriter。
我们会采取一些特殊的步骤来恢复失败的消息,后面的代码会详细介绍restart的实现细节。 大多数时候,我们不想重新处理之前导致错误的消息,因为它很可能还会发生同样的错误。例如:日志处理程序碰到一个损坏的文件,重新处理还是导致失败,结果是进入不断重试的死循环。 为此,Akka不会把引发失败的消息重新放回邮箱,但是有方法可以做到,如果你确信这个消息不会引发错误,你可以调用此方法来实现,这个我们后面会讨论。 好消息是,当一个job处理上万个消息时,如果有一个消息失败,不影响其他消息的处理结果;也就是一个损坏的文件不会导致灾难性的后果(其他处理到这一步的消息继续处理,不用重新处理)。
下图显示了dbWriter崩溃时,supervisor如何重启dbWriter。

让我们回顾一下怎么处理崩溃:
- 故障隔离:supervision决定如何终止actor,actor从actor系统中移除。
- 结构:actor系统的层次关系使得一个actor实例被移除后,其他的actor不受影响。
- 冗余:一个actor可以被另一个替换。例子中,当actor实例的数据库连接发生异常时,可以用连接另外一个数据库的actor替换。 这些都有supervision来决定。 另外一种做法是把消息路由到负载均衡的其他实例,第八章会介绍。
- 更换:一个actor可以从它的Props重建。 supervision可以在不actor实现细节的情况下,用一个新的actor实例替换有缺陷的actor实例。
- 重启:通过restart实现。
- 生命周期:一个actor是一个活动的组件,它可以被启动、停止和重启。 下一节我们详细介绍生命周期。
- 挂起:当actor崩溃,它的邮箱会被挂起,直到supervisor决定如何处理这个actor
- 问题分离:actor的正常消息处理和supervision的故障恢复是正交的, 可以完全独立的定义和设计。
后面几节,我们将介绍生命周期和监管策略的编码细节。